为什么有HTTP还要RPC
省流版
RPC是一套方法论描述,HTTP是一种7层网络协议。这两个东西其实完全是正交的,没有啥可比性。RPC没有明确的协议标准,可以基于http,也可以基于tcp/udp。正因为缺少标准才有涌现出GRPC、thrift,dubbo多种版本框架,各个框架都是基于自己的理解去实现的。
背景
从第一次接触 RPC 后,这个疑惑就一直萦绕在我脑海中,但纵观整个编程史,大家都在心照不宣的使用 RPC,就好像本该如此。于是在好奇心的驱使下去搜了搜这个问题,才算是搞懂了这个问题。
然而答案却让我傻了眼,RPC 比 HTTP 更早出世!这让我大为震惊,由于入坑编程开始第一个接触的就是 HTTP 协议,且在往后的开发中不停的与 HTTP 在打交道,因此一个错误的观点就先入为主了 —HTTP 比 RPC 更早诞生。好了,现在问题演变为《既生 RPC 何生 HTTP》,这就得从大家熟背于心的八股文 —TCP 开始讲起。
TCP
TCP 协议,大白话来解释就是两台服务器想要进行通信,就得用到的一个玩意。
大概过程就是两台服务器会经过一个三次握手的过程来建立一个可靠的连接,然后双方就可以基于这个连接来互相发送消息。那这里就会有个问题:TCP 已经可以做到服务器之间的通信,为啥还要去造一个 RPC 出来?
这里就用到八股文里一个最经典的知识,TCP 的三个特点:它是面向连接的、它具有可靠性、它基于字节流。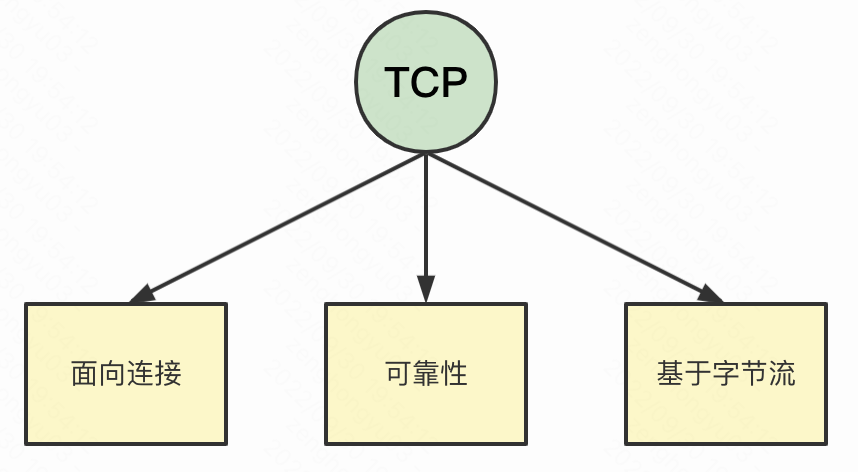
问题就出在了最后一点,TCP 是基于字节流的。字节流可以简单的理解为是一个双向的通道,里面包含二进制数据。而纯裸 TCP 收发的这些二进制数据之间是没有任何边界的,服务器根本不知道到发到哪个地方才算一条完整消息。
就比如 A 服务器此时想向 B 服务器发送 “老铁”+”666”,由于没有边界点,B 服务器接收到的就是 “老铁 666”,这时候 B 服务器没法区分你是想要表达 “老铁”+”666” 还是 “老铁 6”+”66”。
其实这就是个粘包问题,而由这个问题就可以分析出,直接使用裸 TCP 是会有问题的。咱们需要在 TCP 的基础上加入一些自定义的规则来区分消息的边界。于是业界出现了一个流传至今的做法,给消息体拼一个消息头,消息头里会写清楚一个完整的包长度是多少,然后就可以根据这个长度可以继续接收数据,截取出来后它们就是我们真正要传输的消息体。
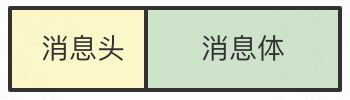
同时这个消息头里还可以放各种各样的东西,只要上下游都约定好了,互相都认就可以了,这就是所谓的协议。每个使用 TCP 的项目都可能会定义一套类似这样的协议解析标准,他们可能有区别,但底层原理都类似。于是基于 TCP,就衍生了非常多的协议,比如 HTTP 和 RPC。
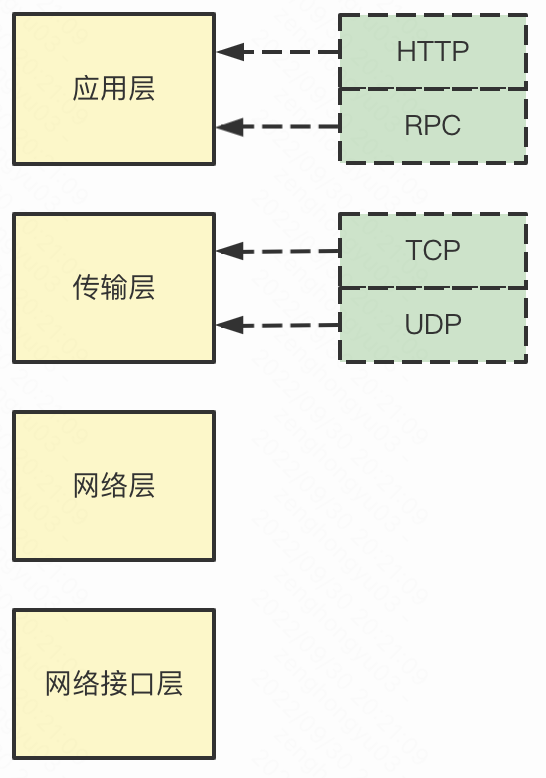
TCP 是传输层的协议,而基于 TCP 造出来的 HTTP 和各类 RPC 协议,它们都只是定义了不同消息格式的应用层协议而已。
HTTP 协议(Hyper Text Transfer Protocol),又叫做超文本传输协议。我们用的比较多,平时上网在浏览器上敲个网址就能访问网页,这里用到的就是 HTTP 协议。
而 RPC(Remote Procedure Call),又叫做远程过程调用。它本身并不是一个具体的协议,而是一种调用方式。它可以让我们程序员用调用本地方法的方式直接去调用远端方法,非常 nice~
既生 RPC 何生 HTTP
上面已经阐述了 HTTP 和 RPC 诞生的由来,那么问题继续回到为什么有了 RPC 还要造个 HTTP?
“艺术来源于生活” 这句名言就可以大致回答这个问题,为什么有了 RPC 还要造个 HTTP,因为随着时代的发展,RPC 不够用了呗(或者说不再适用了)。比如我们会在电脑上装各种软件,比如 xx 管家,xx 卫士,它们都作为客户端(client)需要跟服务端(server)建立连接收发消息,此时都会用到应用层协议,在这种 client/server (c/s) 架构下,它们可以使用自家造的 RPC 协议,因为它只管连自己公司的服务器就 ok 了。
但有个软件不同,浏览器(browser),不管是 Chrome 还是 IE 还是某度,它们不仅要能访问自家公司的服务器(server),还需要访问其他公司的网站服务器,因此它们需要有个统一的标准,不然大家没法交流。于是,HTTP 就是那个时代横空出世,用于统一 browser/server (b/s) 架构的协议。
也就是说很多年以前,HTTP 主要用于 b/s 架构,而 RPC 则更多用于 c/s 架构。但现在随着移动互联网的发展,二者其实已经在慢慢融合了。很多软件同时支持多端,比如我手,既能支持网页版,还能支持手机端和 pc 端,如果通信协议都用 HTTP 的话,那服务器只用同一套就够了。而 RPC 就开始退居幕后,一般就用于公司内部集群里各个微服务之间的通讯。那话这么说,不就回到了文章题目了吗?HTTP 这么强大,还用啥 RPC?
HTTP 和 RPC 的区别
这就不得不来分析下 HTTP 与 RPC 的区别了,最明显的就是以下几个点。

服务发现
服务器直接想要通信就得建立连接,而建立连接的前提就是发送端得知道接收端的 IP 地址与端口号。这个找到服务对应的 IP、端口的过程,其实就是服务发现。HTTP 来实现这个过程就只需要知道该服务的域名,就可以通过 DNS 服务去解析得到它背后的 IP 地址,默认 80 端口。而 RPC 一般会有专门的中间服务区保存服务名与 IP 地址,比如常用的 Nacos、Consul、Zookeeper。
连接形式
以主流的 HTTP1.1 协议为例,它连接形式为底层建立一条 TCP 连接,再次之后可以一直保持这个连接(keep alive),后续的请求都可以复用这条连接。而 RPC 虽然底层也是建立一条 TCP 连接,但 RPC 一般还会再建个连接池,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用,如此循环利用。
序列化方式
基于 TCP 传输的消息,说到底,无非都是消息头 header 和消息体 body。而接收端真正需要的就是 body 中的二进制数据,毕竟计算机只认识这玩意。字符串跟数字都可以很好的转成二进制数据,但复杂的结构体就不行了。为了解决这个问题,json 与 protobuf 就应应而生了。
这个将结构体转为二进制数组的过程就叫序列化,反过来将二进制数组复原成结构体的过程叫反序列化。
对于主流的 HTTP1.1,它采用了 json 序列化的方式,而 RPC 则采用了 protobuf 来进行序列化。这两种方式的区别就在于。json 会显得内容非常的冗余,如下图,像 header 里的那些信息,其实如果我们约定好头部的第几位是 content-type,就不需要每次都真的把 “content-type” 这个字段都传过来,类似的情况其实在 body 的 json 结构里也特别明显。
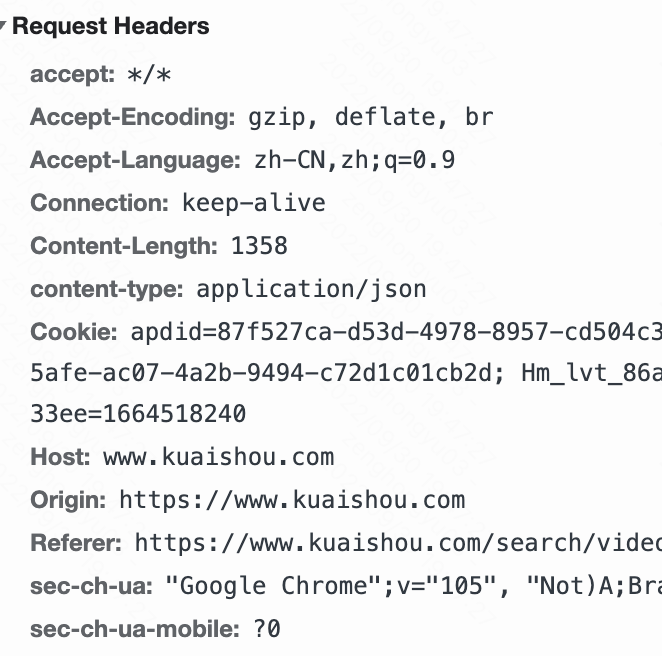
而 protobuf 它的体积更小,可以定制化的去保存结构体数据,同时也不需要像 HTTP 那样考虑各种浏览器行为,比如 302 重定向跳转啥的。因此性能也会更好一些,这也是在公司内部微服务中抛弃 HTTP,选择使用 RPC 的最主要原因。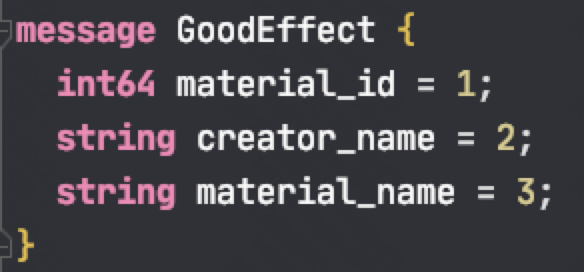
HTTP2
当然上述的情况是基于 HTTP1.1 分析的,而在 2015 年的时候 HTTP2 就出来了,它基于前者做了很多改进,性能可能比很多 RPC 协议都还好,甚至连 gRPC 底层都直接用的 HTTP2。但由于在 HTTP2 出现前,RPC 已经深得微服务心,且服务都已经跑了很多年了,也就没必要再大刀阔斧的换成 HTTP2 了。
总结
套用某乎一位答主的非常精辟的一句话来总结:HTTP 好比普通话,RPC 好比内部黑话。讲普通话的好处就是谁都听得懂,谁都会讲。讲黑话的好处是可以更精简、更加保密、更加可定制,坏处就是要求听黑话的那一方(client 端)也要懂,而且一旦大家都说一种黑话了,换黑话就困难了。