Protocol Buffers 学习笔记
文章摘要:学习 Protobuf 时整理,主要介绍 Protobuf 特性、proto 语法以及 Protobuf 编码方式
前言
Protocol Buffers(Protobuf)
Protocol Buffers 是一种跨语言、跨平台、可扩展的数据格式(序列化方式),与 Json、XML 相比,Protocol Buffers 的性能更高(占用空间更少,序列化和反序列化速度更快)。
Protobuf 的优秀特性
- 跨语言:Protobuf 支持多种变成语言,统一使用 Protobuf 定义数据结构,然后使用 Protoc 生成不同语言的序列化和反序列化代码。
- 跨平台:Protobuf 是平台无关的,不依赖特定的系统架构,可以在不同操作系统和硬件平台运行。
- 向后兼容:proto3 中所有字段都是可选的,如果没有赋值,序列化时不会被包含,反序列化时会被初始化为默认值。
- 高性能:Protobuf 使用二进制存储,并且采用变长整数以及字段编号,使得其序列化后占用空间更少,并且序列化和反序列化速度更快。
- 安全性:没有结构描述文件,则无法解析实际内容,安全性更高。
Proto 文件
.proto 文件用来定义消息类型和服务接口,使用 Protobuf 语言编写。
Protoc
protoc 是 Protobuf 的编译器,可以根据 Protobuf 的定义文件 .proto 生成多种语言(如:C++, Java, Go, Python 等)的类型定义文件及编解码操作代码。
Protobuf 语法
.proto 文件示例
1 | // 选择proto2或者proto3的语法,这里指定了proto3的语法 |
关键字
- syntax:指定 proto 版本
- package:指定包
- option:option 关键字用于为 proto 文件中不同实体提供额外的、可配置的选项
- import:引入外部依赖
- message:定义消息类型(Java 中的类)
- enum:定义枚举类型(Java 中的枚举类)
- service:定义服务
option 选项
完整的 option 功能可见 Protobuf Options
文件级别 option
文件级别的 option 应用于整个. proto 文件,它们通常位于文件的顶部,不包含在任何消息、枚举或服务定义中。
1 | // 控制为.proto文件中每个消息和枚举生成一个单独的Java文件 |
消息级别 option
消息级别的 option 定义在消息类型的内部,但不属于任何字段。它们影响该消息类型的代码生成。
例如,你可以为生成的 Java 类指定一个不同的类名:
1 | message MyMessage { |
字段级别 option
字段级别的 option 定义在消息字段定义之后,并且只影响该字段。
例如,可以为字段指定一个默认值,或标识弃用字段
1 | message MyMessage { |
自定义 option
Protobuf 还支持自定义选项,但一般用不到
数据类型
- 基本数据类型:bool、int32、int64、uint32、uint64、float、double、string、bytes。
- 枚举类型:使用关键字 enum 定义。
- 消息类型:使用关键字 message 定义。
- Oneof 类型:表示这些字段中只能有一个字段被设置了值。
- Map 类型:表示 key-value 映射关系的数据类型。
- Any 类型:表示任意类型的数据。
- Duration 类型:表示时间间隔。
- Timestamp 类型:表示时间戳。
详细见 proto 数据类型
如何定义 message
1 | message Order { |
message 中字段定义格式:[字段标签] 字段类型 字段名称 = 字段编号。
message 和 Java 中的类定义非常像,需要注意的就是字段编号。
字段编号
字段编号用于唯一标识字段,在序列化时会把字段编号和字段值编码成二进制数据,反序列化时也是解析出字段编号来定位到是哪个字段。每个字段必须分配字段编号,同一个消息中字段序号不能重复。
📌
字段编号虽然没有强制规定必须递增分配,但建议字段编号从 1 开始递增,这样可以避免重复,而且较低的编号值会占用更少的空间,比如 1-15 占用 1 字节,16-2047 占用 2 字节,具体原因可以见 Protobuf 编码。
字段标签
如果想定义 List 类型或者 Map 类型需要用到字段标签 repeated 和 map,proto 中的字段标签如下:
- repeated:对应 Java 的 List,比如 repeated int32 items = 3; // 物品列表
- map:对应 Java 中的 Map,比如 map<string, string> ext_data = 5; // 扩展字段
- optional(proto3 中已废弃):被 optional 标识的字段表示是可选的,如果没有被赋值则在序列化时不会包含,proto3 中所有字段均是可选的。
proto3 中,如果字段没有被赋值,在反序列化时会被赋值为字段默认值,也可以在 proto 文件中使用 default 选项指定字段默认值。
如何定义 enum
1 | enum PaymentMode { // 支付方式 |
与 Java 中枚举类的区别时,proto 中 enum 不支持为枚举值定义多个字段,只包含枚举值名称枚举值 = 字段编号
如何定义 service
1 | // 定义一个请求消息 |
service 关键字定义一个服务,在服务内使用 rpc 关键字定义 rpc 接口,需要指定参数类型和返回值类型
Protobuf 编码
看一个简单的消息定义,以及序列化后的字节流
1 | message Test1 { |
这段字节流解析出来的内容是这样的:(工具:https://protobuf-decoder.netlify.app/)
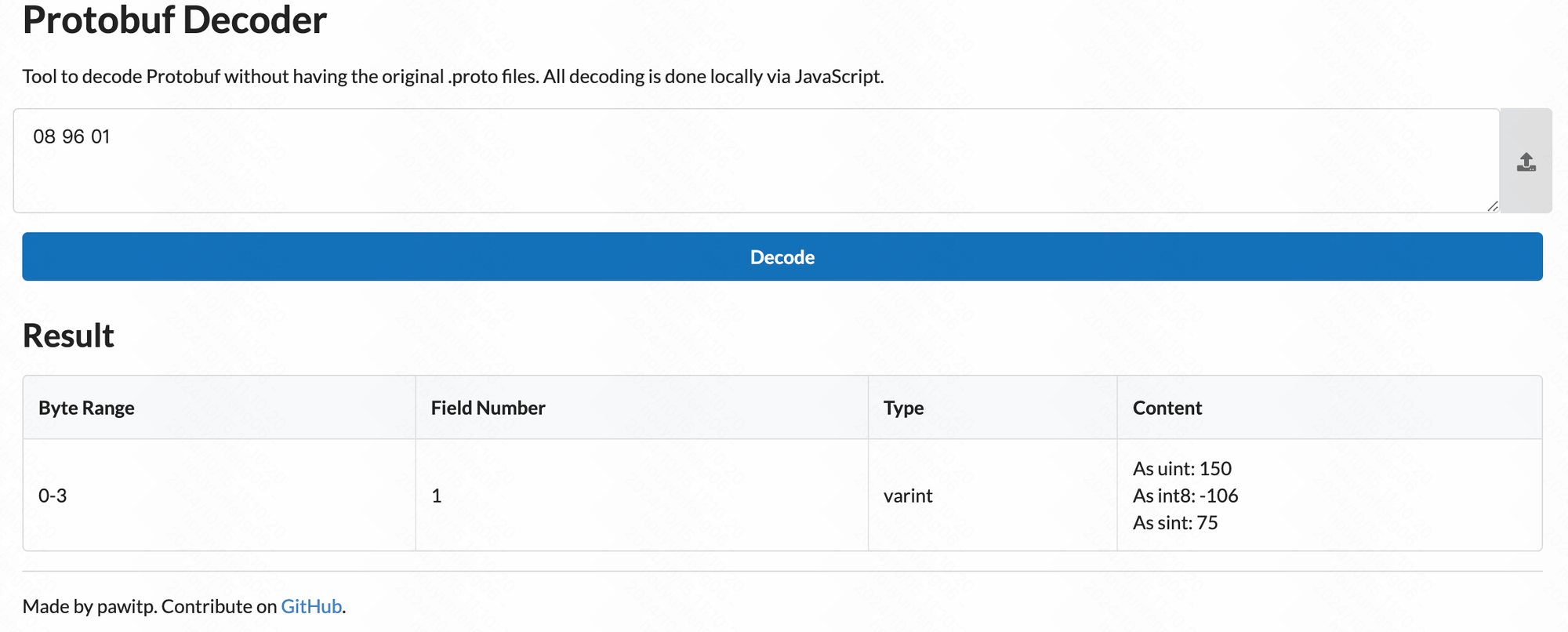
可以看到解析出来的信息有
- 字段编号为 1
- 字段类型为 varint
- 字段值为 150
KV 格式
序列化后的字节流是一个个的 kv 对,即第一个字节开始表示 key,然后紧接着是这个 key 对应的 value,后面依次是 key value key value ……。在这个例子中 08 就是 key, 96 01 就是 value,那么有两个问题:
- 08 怎么解析出字段编号为 1,字段类型为 varint?
- 为什么 value 是 96 01 而不是 96,怎么判断其占用两个字节,96 01 怎么解析成 150?
第一个问题:key 的解码方式
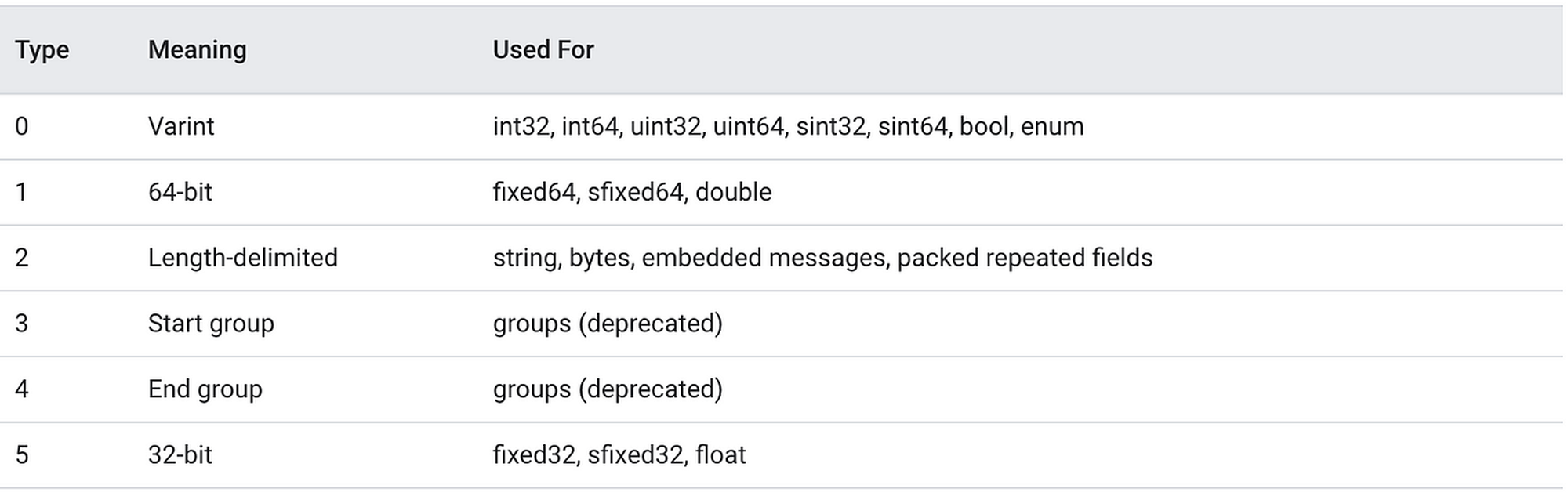
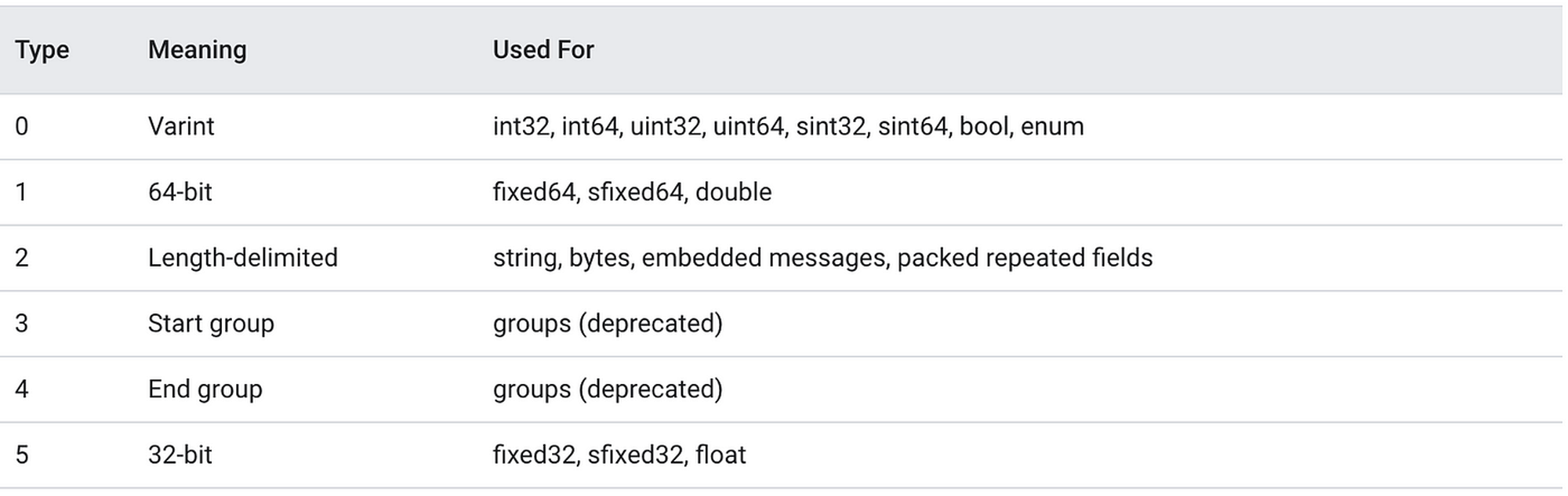
key 的低 3 位表示数据类型,高 5 位表示字段编号,比如 08 的解码逻辑如下:
1 | key 8的解码逻辑: |
类型 0 对应的就是 varint 类型(变长整数)
第二个问题:变长整数
变长整数是 protobuf 编码的核心。它允许使用 1 到 10 个字节对无符号 64 位整数进行编码,小值使用较少的字节。
变长整数中的每个字节都有一个延续位,该位指示其后的字节是否是变长整数的一部分。延续位是字节的最高有效位(MSB)(有时也称为符号位)。较低的 7 位是有效载荷;通过将组成字节的 7 位有效载荷附加在一起来构建结果整数。
比如整数 1 占用 1 字节,表示为:
1 | 0000 0001 |
接下来看 96 01,其二进制表示如下:
1 | 10010110 00000001 |
这段二进制码如何解析为 150 ?
- 第一个字节的 MSB 为 1,第二个字节的 MSB 为 0,以此确定其占用两个字节
- 然后分别取出其 7 位有效载荷
- 这些 7 位有效载荷按照小端排列,将其转换为大端顺序
- 连接并转换为 10 进制
1 | 10010110 00000001 // 原始输入 |
附录
proto 数据类型
| proto 类型 | Java 类型 | 默认值 | 说明 |
|---|---|---|---|
| int32 | int | 0 | 32 位整数 |
| int64 | long | 0 | 64 位整数 |
| uint32 | int | 0 | 32 位无符号整数 |
| uint64 | long | 0 | 64 位无符号整数 |
| sint32 | int | 0 | 32 位有符号整数 |
| sint64 | long | 0 | 64 位有符号整数 |
| bool | boolean | 0 | 布尔类型 |
| fixed32 | int | 0 | 32 位固定长度编码 |
| fixed64 | long | 0 | 64 位固定长度编码 |
| sfixed32 | int | 0 | 32 位有符号固定长度编码 |
| sfixed64 | long | 0 | 64 位有符号固定长度编码 |
| float | float | 0.0 | 32 位浮点数 |
| double | double | 0.0 | 64 位浮点数 |
| string | String | “”(空串) | UTF-8 编码字符串 |
| bytes | ByteString | “”(空 ByteString) | 任意字节序列 |
| enum | enum | 枚举类型第一个值 | 枚举类型 |
| messages | class | null | |
| repeated | List | 空列表 | |
| map | Map | 空映射 |
proto 编码格式