Redis实现排行榜功能
背景
通常来说,榜单是指一定时间周期内以某个指标反序排列的 N 个元素 (id, score),即 topN 个元素,这里的 N,一般来说是个较小的常数,如 100。而根据时间周期的不同,可分为小时榜、日榜、周榜、月榜等。
以直播为例,在直播后端业务场景下,涉及榜单的包括但不限于直播间榜单、直播 PK 贡献榜单、粉丝团亲密度榜单、直播宠物好友榜单、直播宠物投喂饭团榜单、地区小时榜单。其中直播间榜单是日榜、直播 PK 贡献榜则是以 PK 时长为周期的榜单。
本文主要简述在不同需求场景下,如何使用 redis 对榜单数据进行存储,并尽可能保证榜单数据一致性。
概念
- 榜单,一系列榜单单元 <id, score> 构成,按 score 反序排列的有序列表。
- 榜单元素,id,用户于惟一标识榜单中某个数据单元,如用户 id;score,用于标识 id 的计分。
- 说明:后续示例中以 u 表示用户,topList 表示榜单,userScore 表示用户计分。
选择 redis 原因
- redis 丰富的数据结构中 zset 就是有序列表。
- redis zset 支持按给定下标区间、score 区间访问列表,删除元素。
- redis server 是单线程执行的,client 合理调用足以保证榜单列表更新是线程安全的。
场景分析
case1. 榜单用户少
- 说明:进入榜单的总用户量在一定数据量级,如 1000 以内。
- 方案:榜单直接采用一个 zset 存储全量的用户数据即可。
- 读写逻辑的代码也很简单。
1 | public void updateUserScore(String key, long userId, long delta) { |
case2. 榜单用户多 & 可容忍偶尔不一致
简单说一下使用榜单用户少相同方案的问题,即大 key 问题;因此采用一个 zset 来存储大量榜单用户并不合适,由背景陈述可知榜单一般来说需要保存的是 topN 的用户,因此可如此解决:
- 用户计分单独存储,即采用 redis k-v 存储用户计分;
- 榜单 (topList) 仅存储 topN 个用户的计分;
- 读写逻辑稍微复杂那么一点点哈。有个小细节,NEED_TRIM_SIZE 和 RETAIN_SIZE 不要用一样的,容易导致一直发生删除操作,或者采用概率性的 zrem 也 ok。
1 | public void updateUserScore(String key, long userId, long delta) { |
case3. 榜单用户多 & 一致性要求高
一致性分析
为啥要区分 case2 和 case3 呢,因为 case2 在并发场景下,可能导致榜单中用户数据出错,如下图所示,当然同一进程内并发也会出现,以下只是可选示例中的一种,最终用户 u1 在榜单中的分数为 90,实际应该为 110。本文提供了三种可供选择的解决方案。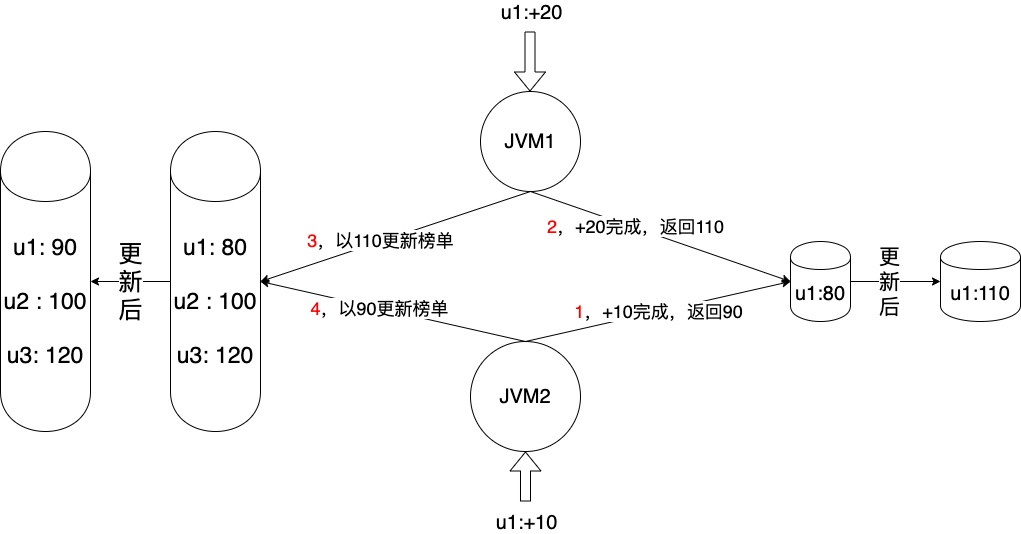
方案 1. 结合工具避免用户级并发
- 将基础数据 (userId, score),按 userId 分 partition 发消息;
- 消费侧 consumer,以 userId 为 key 采用亲缘性线程池进行消费;
- 这种解法前置过程就不展示代码了,对于榜单相关数据的操作就是和 case2 一样。
- 缺点是可能丢消息或者单个用户热点数据也是可能的,这就得 case by case 了。
方案 2. lua 实现 (PS:咱公司不建议使用,看看就好)
- 直接上代码吧
1 | private static final String LUA_SCRIPT = "local var = redis.call('zscore',KEYS[1], ARGV[1]) " |
- 一致性得到保障原因如下图所示
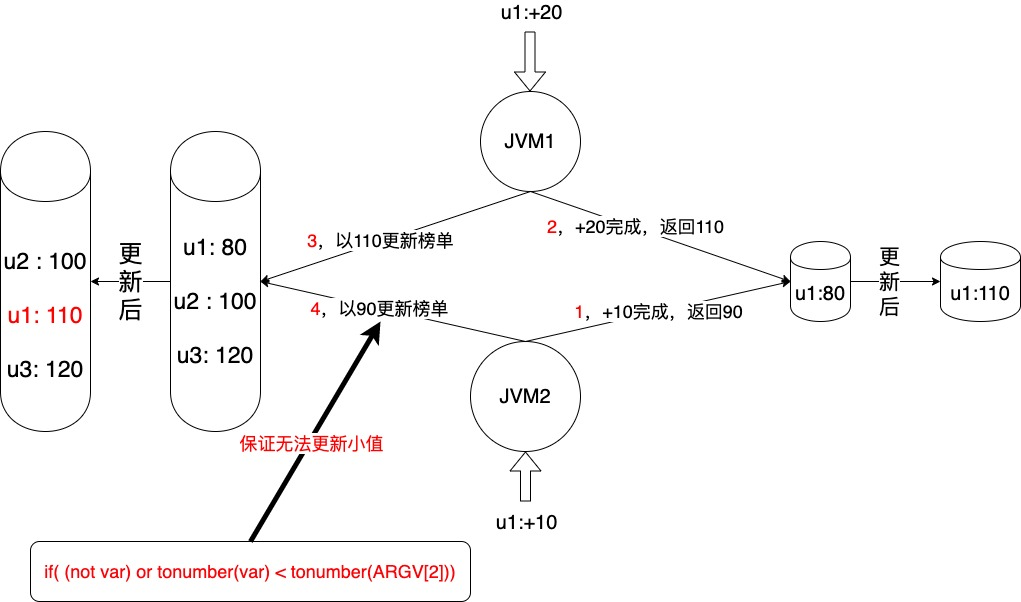
方案 3. 逻辑硬刚
由上可知,问题的核心在于保证榜单中用户数据的正确更新,从上述 lua 脚本的方案可以看出来,对于同一用户的操作保证串行就行了。
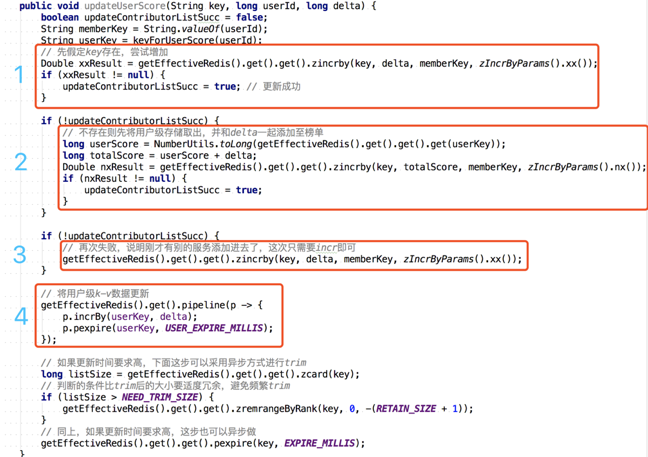
换个思路,如果对于用户加分的操作区分两个场景。1、用户当前在榜单执行加分操作;2、用户当前不在榜单执行全量更新,也能尽量避免上述讨论的时序问题导致数据最终不正确的问题。如用户 u 当前 80 分,现在执行一个加 10 分操作,具体步骤如下:
- 先假设用户 u 在 topList 中存在,对 topList 中 u 用户执行存在则加 10 分操作 (XX),成功则完事走第 4 步,否则进第 2 步;
- 第 1 步失败了,说明用户 u 不在 topList 中,则对用户 u 使用 90 分 (80+10),在 topList 里执行设置 90 分操作 (NX),成功则完事走第 4 步,否则进第 3 步;
- 第 2 步失败了,说明用户 u 被别的线程设置上了,再对 topList 中 u 用户执行存在则加 10 分操作 (XX),成功则成功,失败则失败,失败概率很小很小,后文会讲,这里不会再兜底了;
- 对用户级的计分进行更新;
- 具体代码如图
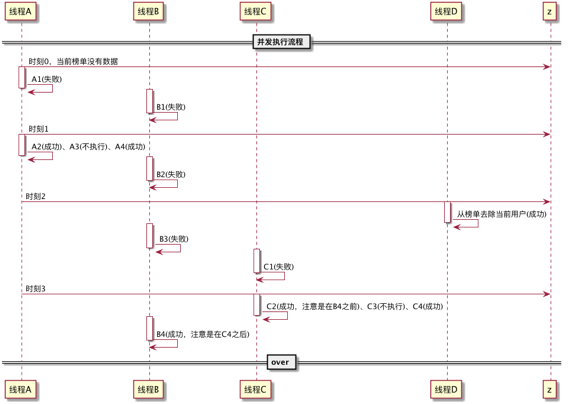
我能想到的方案 3 中出现一致性问题的场景如下,欢迎补充~~~
1 | 线程A: |
case4. 榜单用户多 & 分数有增减
- 问题:由于用户的分数会减少,即榜单上的用户会有主动掉出榜单的场景,这种情况下现有方案就无法实现从非榜单用户之外的用户找到一个合适的用户添加到榜单中。
- 示例:比如榜单存储了 top100 的用户,当第 100 名用户分数下降后,无法确定该用户还是不是第 100 名,也无法找出真正的第 100 名了。
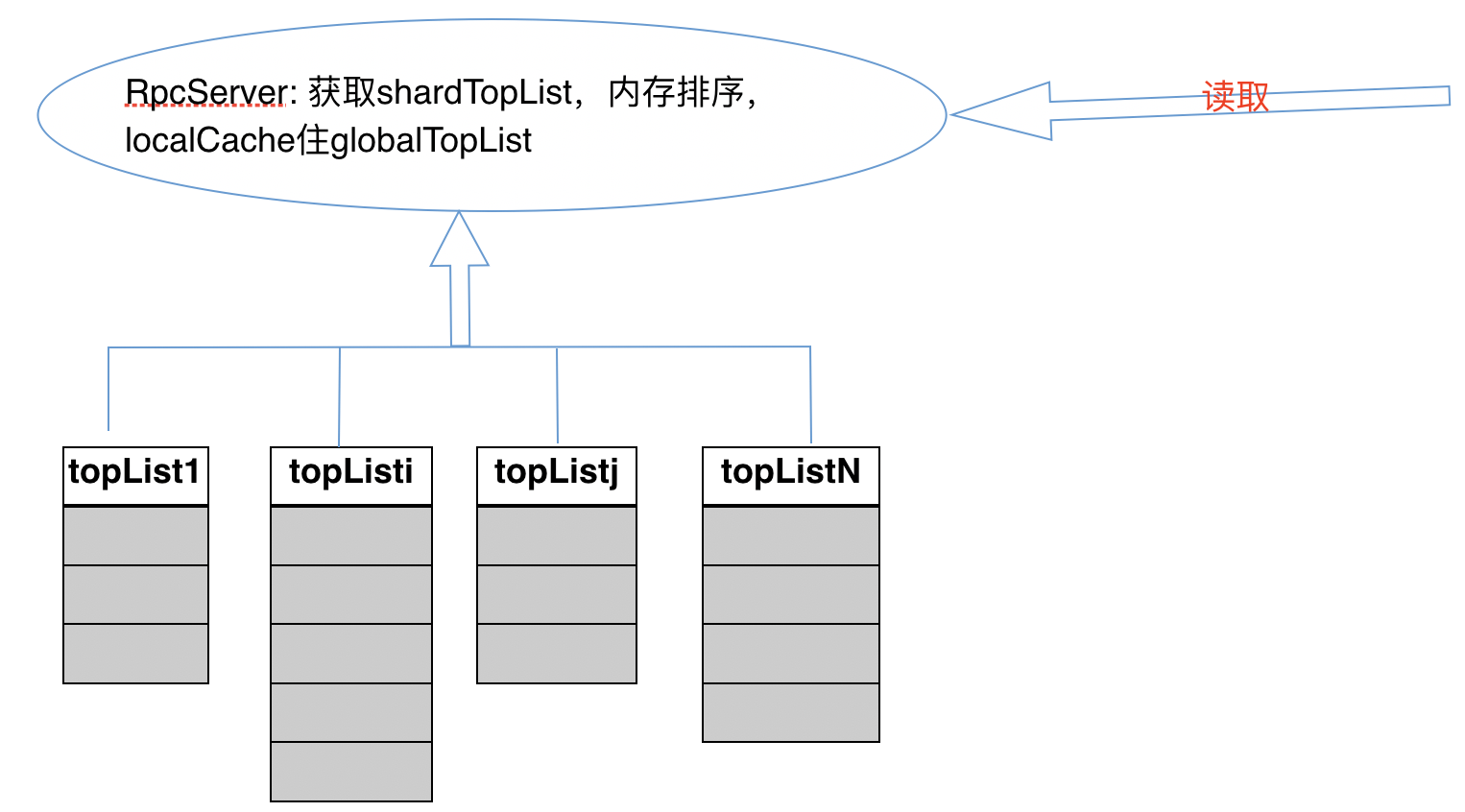
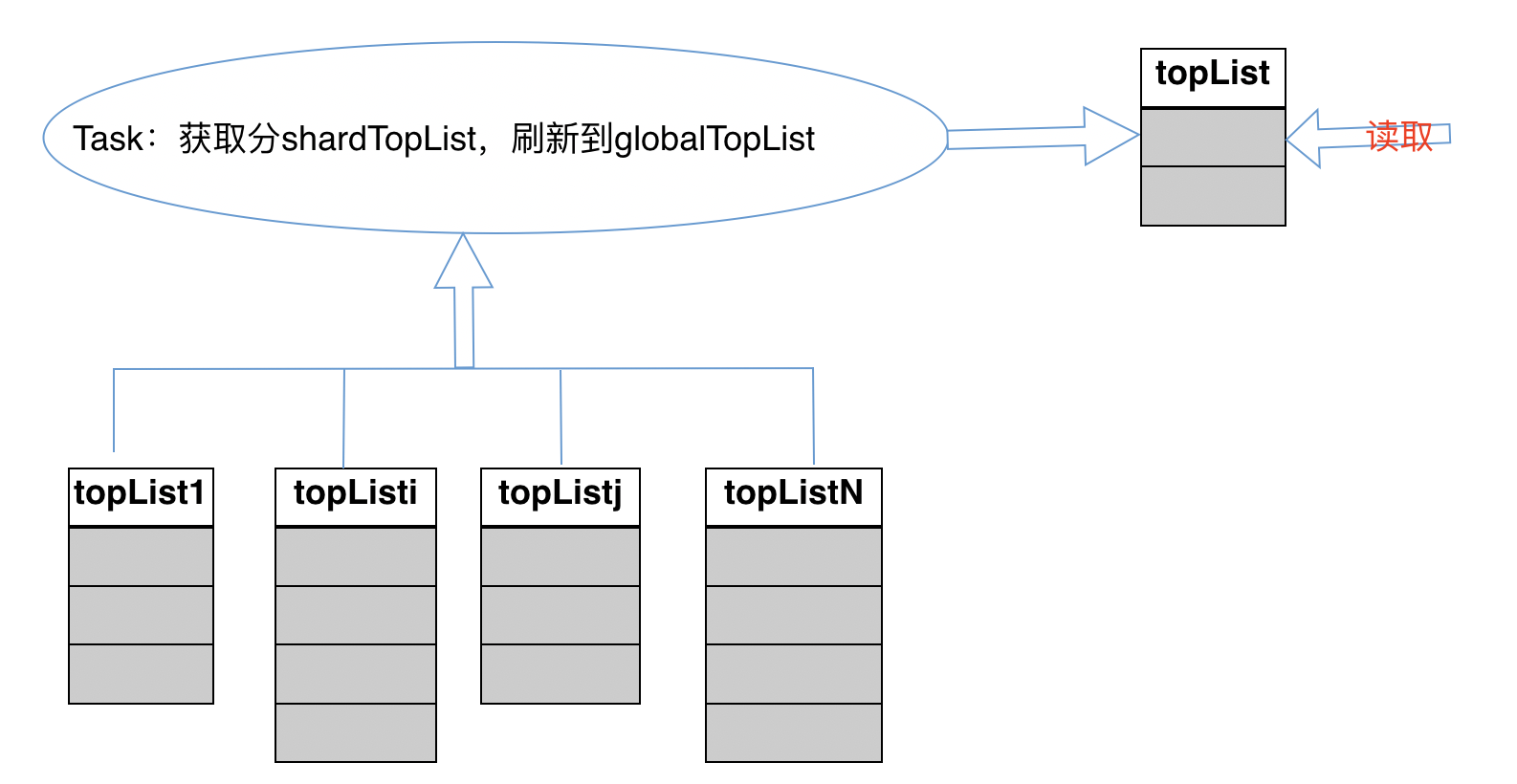
- 方案:采用多个 zset 分 shard 存储全量用户数据,再通过一个中间服务 (个人不建议) 或者读时内存聚集的方式获取总榜。当然这里的总榜如果有单独存储的话,用 memcache 更佳。
- 中间服务读取
独立总榜存储
总结
- 用户量小:单个榜单全量用户直接扛
- 用户量大:用户 k-v,榜单 trim 保存部分用户扛
- 用户量大 & 强一致性:用户 k-v,榜单 trim 扛,逻辑保证原子更新
- 用户量大 & 有增有减:shard 榜单扛局部用户,总榜通过再服务的方式提供查询或单独存储